
UEFA Conference League Exploratory Data Analysis Tutorial
A tutorial of exploratory data analysis (EDA) through my love for Shamrock Rovers F.C. and their journey so far in 2024-2025 Uefa Conference League

Introduction
This tutorial has provided an overview of the exploratory data analysis (EDA) process using R and is for illustrative purposes only. There are people much smarter than me who can do much better work, I just like to learn and share new skills!
The dataset used in this tutorial is from the 2024-2025 Uefa Conference League and is a collection of data made available by the FBREF website. The dataset includes information on the matches, players, and teams involved in the competition. For the purpose of this tutorial, we will focus on the basics of EDA, including data cleaning, data visualization, and data analysis. We will also learn how to merge datasets, create new variables, and perform basic statistical analysis.
Scraping Data
Load libraries for Web Scraping
The first step in the EDA process is to scrape the data from the web. We will use the rvest package to scrape the data from the FBREF website. The rvest package is a powerful tool for web scraping in R and allows us to extract data from HTML and XML documents. We will also use the tidyverse package for data manipulation and visualization. The stringr package is used for string manipulation, and the readr package is used for reading and writing data. Finally, the openxlsx package is used for reading and writing Excel files.
library(rvest)
library(tidyverse)
library(stringr)
library(readr)
library(openxlsx)
Define the Live HTML URLs for each Stats Web Page from FBREF
Next we need to define the URLs for each of the web pages we want to scrape. Defining these URLs initially will allow us to easily access the data we need later on in the tutorial. We will scrape the following pages:
general_stats_url <- "https://fbref.com/en/comps/882/stats/Conference-League-Stats"
gk_url <- "https://fbref.com/en/comps/882/keepers/Conference-League-Stats"
adv_gk_url <- "https://fbref.com/en/comps/882/keepersadv/Conference-League-Stats"
shooting_url <- "https://fbref.com/en/comps/882/shooting/Conference-League-Stats"
passing_stats <- "https://fbref.com/en/comps/882/passing/Conference-League-Stats"
passing_types_stats <- "https://fbref.com/en/comps/882/passing_types/Conference-League-Stats"
creation_stats <- "https://fbref.com/en/comps/882/gca/Conference-League-Stats"
defensive_stats <- "https://fbref.com/en/comps/882/defense/Conference-League-Stats"
possession_stats <- "https://fbref.com/en/comps/882/possession/Conference-League-Stats"
playing_time_stats <- "https://fbref.com/en/comps/882/playingtime/Conference-League-Stats"
misc_stats <- "https://fbref.com/en/comps/882/misc/Conference-League-Stats"
Collecting the Data
The first step in collecting the data we need is to read the live HTML tables from the FBREF website. We will use the read_html function from the rvest package to read the HTML content of the web pages. We will then use the html_table function to extract the tables from the HTML content. First, we will read the general statistics table however this process can be repeated for all the other URLs defined above.
Read the live html tables
The read_html_live function reads the HTML content of the web page and extracts the tables from the HTML content. We will use this function to read the live HTML tables from the FBREF website.
general_html <- read_html_live(general_stats_url) %>%
html_table(fill = T)
Next, we need to identify which table we are interested in.
general_table <- general_html %>%
.[[1]] %>%
as.data.frame()
Clean up the data frame
The next step is to clean up the data frame by removing any unnecessary columns and rows. We will also rename the columns to make them more readable. We can clean up the data frame by removing the first row, which contains the column names, and setting the column names to the first row of the data frame.
colnames(general_table) <- general_table[1,] # Set column names to first row
general_table <- general_table[-1,] # Remove first row
Now that we have set the column names to the first row of the data frame, we can clean up the column names using the janitor::clean_names function. This function will remove any special characters and convert the column names to lowercase.
general_table <- janitor::clean_names(general_table)
Next, we need to remove any unnecessary columns from the data frame. We can do this by selecting only the columns we are interested in using the select function from the dplyr package. As we are only interested in team statistics and some data is duplicated within other columns, we can remove the duplicated data. The columns we are interested in are:
startsminx90s
We also need to move the mp column before the poss column as it is more relevant to the data.
general_table_clean <- general_table %>%
select(-c(starts, min, x90s)) %>%
select(squad, number_pl, age, mp, everything())
Next we need to tackle the variable types of the columns. The data in the columns is currently stored as character data, so we need to convert these columns to numeric data using the as.numeric function. We can use the mutate function from the dplyr package to apply the as.numeric function to all the numeric columns in the data frame.
general_table_clean <- general_table_clean %>%
mutate(across(2:ncol(general_table_clean), as.numeric))
Now that we have fixed the variable types of the columns, we can move on to the next step, which is to rename the columns to make them more descriptive. We can use the rename function from the dplyr package to rename the columns. We will rename all columns in the data set so that we can quickly identify the data needed for future analysis - this is a personal preference, as there is nothing worse than knowing what the data is but not what it represents!
general_df <- general_table_clean %>%
rename(
team = squad,
no_of_players_used = number_pl,
age = age,
matches_played = mp,
avg_possession_perc = poss,
goals = gls,
assists = ast,
goals_and_assists = g_a,
non_penalty_goals = g_pk,
penalty_goals = pk,
penalty_attempts = p_katt,
yellow_cards = crd_y,
red_cards = crd_r,
xGoals = x_g,
non_penalty_xG = npx_g,
xAssisted_Goals = x_ag,
non_penalty_xGoals_plus_Assisted_Goals = npx_g_x_ag,
progressive_carries = prg_c,
progressive_passes = prg_p,
goals_90 = gls_2,
assists_90 = ast_2,
goals_and_assists_90 = g_a_2,
non_penalty_goals_90 = g_pk_2,
non_penalty_goals_plus_assists_90 = g_a_pk,
xGoals_90 = x_g_2,
xAssisted_Goals_90 = x_ag_2,
xGoals_plus_xAssisted_Goals_90 = x_g_x_ag,
non_penalty_xGoals_90 = npx_g_2,
non_penalty_xGoals_plus_xAssisted_Goals_90 = npx_g_x_ag_2
)
Now that we have a full clean data frame, we can simply view the data to ensure it is structured correctly. For this we can use the head function to view the first 6 rows of the data frame. Alternatively, we could use the view function to view the data frame in a separate window or use the glimpse function to view the structure of the data frame.
head(general_df)
Having viewed the data, we can see that there is still an issue with the team column. The team names are correctly stored as character data, however the abbreviated nation also displays in the same column. In this instance we need to remove everything before the first capital letter in the team column. To do this we can use the gsub function from the base package to remove everything before the first capital letter in the team column. The regular expression .*?([A-Z].*) will match everything before the first capital letter in the team column and replace it with an empty string. The \\1 in the replacement string refers to the first capture group in the regular expression, which is the team name. It sounds complicated but it gets the job done!
general_df$team <- gsub(".*?([A-Z].*)", "\\1", general_df$team)
Now for the final time we can view the data to ensure it is structured correctly. This time lets use glimpse to view the structure of the data frame.
glimpse(general_df)
write.csv(general_df, "general_df.csv") # Save the data frame to a CSV file
As we can see from the output, the data frame has 27 observations and 27 variables. The data frame is now clean and ready for further analysis. The next step of EDA is to visualise the data using data visualization techniques. The pupose of this step is to gain insights into the data in a systematic way and identify any patterns or trends that may be present.
Data Visualization
EDA is an important step in the data analysis process as it allows us to explore the data and identify patterns or trends that may be present. Data visualization is a key component of EDA as it allows us to visualise the data in a systematic way and identify any patterns or trends that may be present. In this section, we will use data visualization techniques to explore the data and gain insights into the performance of the teams in the 2024-2025 Uefa Conference League. During EDA there are three broad goals:
- Generate questions about your data.
- Search for answers by visualizing, transforming, and modelling your data.
- Use what you learn to refine your questions and/or generate new questions.
It's important to remember that EDA is all about curiosity and exploration. It's about asking questions and finding answers. It's about learning from the data and using that knowledge to make informed decisions. EDA is not a formal process with a strict set of rules - be curious.
Data Visualization Techniques
There are many data visualization techniques that can be used to explore the data. Some of the most common data visualization techniques include:
- Bar charts
- Line charts
- Scatter plots
- Box plots
- Histograms
- Heat maps
- Pie charts
- Bubble charts
- Area charts
- Violin plots
In this section, we will use some of these data visualization techniques to explore the data and gain insights into the performance of the teams in the 2024-2025 Uefa Conference League.
Bar Charts
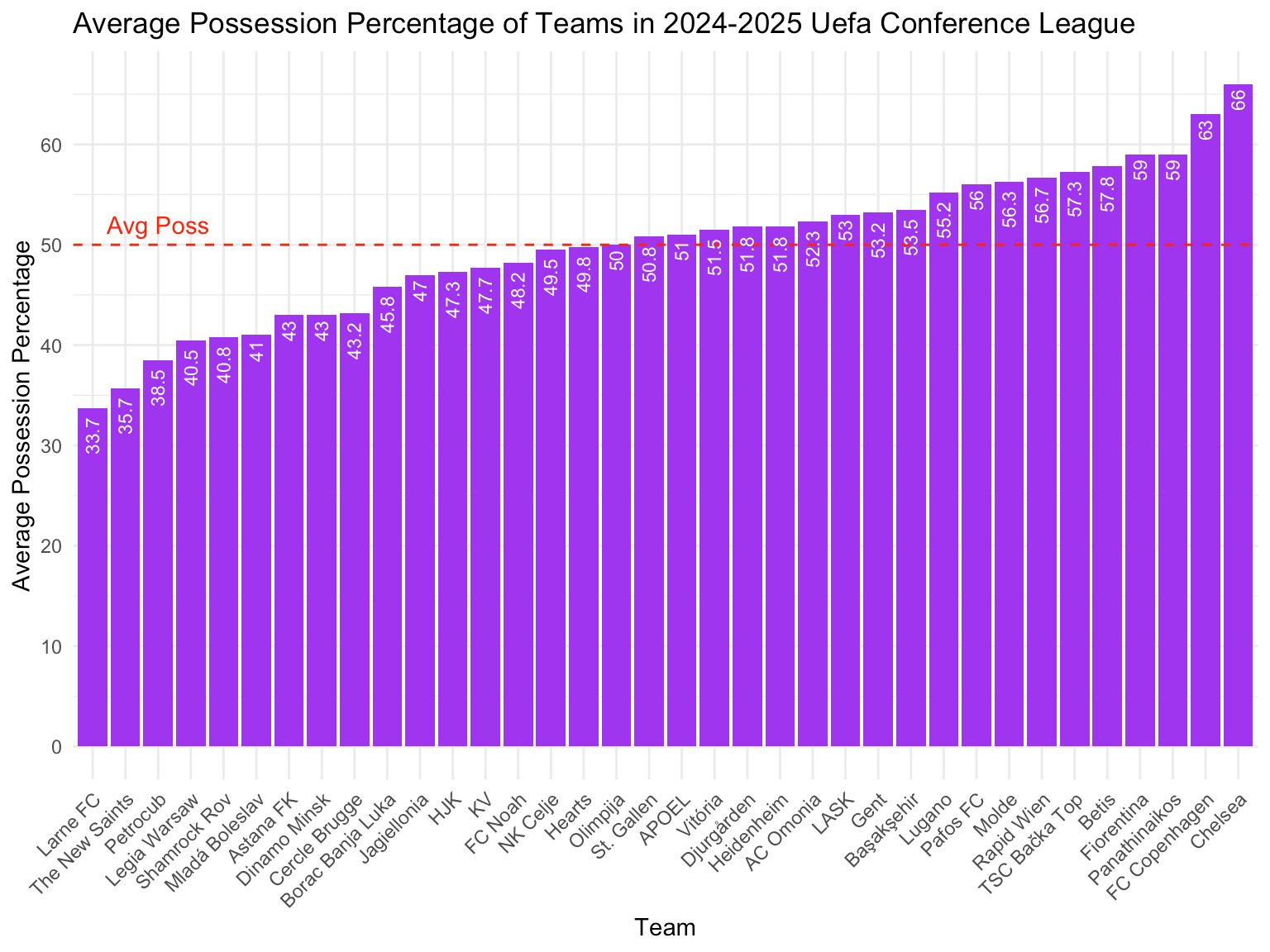
Bar charts are a common data visualization technique that is used to compare the values of different categories. Bar charts are useful for visualizing categorical data and identifying patterns or trends that may be present. In this section, we will use bar charts to compare the average possession percentage of the teams in the 2024-2025 Uefa Conference League.
Average Possession Percentage
The first bar chart we will create is a bar chart of the average possession percentage of the teams in the 2024-2025 Uefa Conference League. We will use the ggplot2 package to create the bar chart and the geom_bar function to plot the data. We will also use the theme_minimal function to set the theme of the plot to minimal.
library(ggplot2)
ggplot(general_df, aes(
x = reorder(team, avg_possession_perc),
y = avg_possession_perc)
) +
geom_bar(stat = "identity", fill = "purple") +
# Add y-axis breaks every 10%
scale_y_continuous(breaks = seq(0, 100, by = 10)) +
labs(title = "Average Possession Percentage of Teams in 2024-2025 Uefa Conference League",
x = "Team",
y = "Average Possession Percentage") +
theme_minimal() +
theme(axis.text.x = element_text(angle = 45, hjust = 1)) +
geom_hline(yintercept = mean(general_df$avg_possession_perc), linetype = "dashed", color = "red") +
annotate("text", x = 3, y = mean(general_df$avg_possession_perc) + 2, label = "Avg Poss", color = "red") +
# Add data labels to fit correctly
geom_text(aes(label = round(avg_possession_perc, 1)), vjust = .5, hjust = 1.25, size = 3, angle = 90, color = "white")

The bar chart shows the average possession percentage of the teams in the 2024-2025 Uefa Conference League. The bar chart is a useful data visualization technique for comparing the values of different categories and identifying patterns or trends that may be present. From the bar chart, we can see that the team with the highest average possession percentage is Chelsea with an average possession percentage of 66%. The team with the lowest average possession percentage is Larne with an average possession percentage of 33.7%. The bar chart provides a visual representation of the data and allows us to quickly identify the teams with the highest and lowest average possession percentages.
Scatter Plots
Scatter plots are a common data visualization technique that is used to visualise the relationship between two variables. Scatter plots are useful for identifying patterns or trends that may be present in the data. In this section, we will use scatter plots to visualise the relationship between the number of matches played and the number of goals scored by the teams in the 2024-2025 Uefa Conference League.
Average Possession vs. Number of Goals Scored
The first scatter plot we will create is a scatter plot of the average possession percentage and the number of goals scored by the teams in the 2024-2025 Uefa Conference League. We will use the ggplot2 package to create the scatter plot and the geom_point function to plot the data. We will also use the theme_minimal function to set the theme of the plot to minimal. The geom_smooth function is used to add a linear regression line to the scatter plot.
ggplot(general_df, aes(
x = avg_possession_perc,
y = goals)
) +
geom_point(aes(color = team)) +
geom_smooth(method = "lm", se = T) +
scale_y_continuous(breaks = seq(0, 50, by = 5)) +
scale_x_continuous(breaks = seq(0, 100, by = 5)) +
labs(title = "Average Possession vs. Number of Goals Scored in 2024-2025 Uefa Conference League",
x = "Average Possession Percentage",
y = "Number of Goals Scored") +
theme_minimal() +
theme(legend.position = "none") +
# Add data labels to fit correctly and ensure they do not overlap
geom_text(aes(label = team), vjust = -.5, hjust = .5, size = 3, color = "black", check_overlap = T)

The scatter plot shows the relationship between the average possession percentage and the number of goals scored by the teams in the 2024-2025 Uefa Conference League. The scatter plot is a useful data visualization technique for visualizing the relationship between two variables and identifying patterns or trends that may be present in the data. From the scatter plot, we can see that there is a positive relationship between the average possession percentage and the number of goals scored by the teams. Teams with a higher average possession percentage tend to score more goals than teams with a lower average possession percentage. The scatter plot provides a visual representation of the data and allows us to quickly identify the relationship between the two variables.
We can validate this relationship by running a simple correlation equation between the two variables. This will provide us with a correlation coefficient which will tell us the strength and direction of the relationship between the two variables. We can use the cor function to calculate the correlation coefficient between the two variables.
shapiro.test(general_df$avg_possession_perc)
cor(general_df$avg_possession_perc, general_df$goals)
The correlation coefficient between the average possession percentage and the number of goals scored by the teams is 0.504074. This indicates a moderate positive relationship between the two variables. The correlation coefficient provides us with a quantitative measure of the relationship between the two variables and confirms the visual relationship we observed in the scatter plot.
Frequency Distribution
Frequency distribution is a common data visualization technique that is used to visualise the distribution of a variable. Frequency distribution is useful for identifying patterns or trends that may be present in the data. In this section, we will use frequency distribution to visualise the distribution of the number of goals scored by the teams in the 2024-2025 Uefa Conference League.
Histogram
The first frequency distribution we will create is a histogram of the number of goals scored by the teams in the 2024-2025 Uefa Conference League. We will use the ggplot2 package to create the histogram and the geom_histogram function to plot the data. We will also use the theme_minimal function to set the theme of the plot to minimal.
ggplot(general_df, aes(
x = goals)
) +
geom_histogram(fill = "purple",
bins = 10) +
scale_x_continuous(breaks = seq(0, 50, by = 1)) +
scale_y_continuous(breaks = seq(0, 10, by = 1)) +
labs(title = "Frequency Distribution of Number of Goals Scored in 2024-2025 Uefa Conference League",
x = "Number of Goals Scored",
y = "Frequency") +
theme_minimal()

The histogram shows the distribution of the number of goals scored by the teams in the 2024-2025 Uefa Conference League. The histogram is a useful data visualization technique for visualizing the distribution of a variable and identifying patterns or trends that may be present in the data. From the histogram, we can see that the most common number of goals scored by the teams is between 7 and 12 goals. The histogram provides a visual representation of the data and allows us to quickly identify the distribution of the number of goals scored by the teams.
Box Plots
Box plots are a common data visualization technique that is used to visualise the distribution of a variable. Box plots are useful for identifying patterns or trends that may be present in the data. In this section, we will use box plots to visualise the distribution of the number of goals and assists by the teams in the 2024-2025 Uefa Conference League.
The first box plot we will create is a box plot of the number of goals and assists by the teams in the 2024-2025 Uefa Conference League. We will use the ggplot2 package to create the box plot and the geom_boxplot function to plot the data. We will also use the theme_minimal function to set the theme of the plot to minimal.
First we need to create categories for the data to be plotted. We will create a new column in the data frame called category which will contain the categories goals_and_assists. We can use the mutate function from the dplyr package to create the new column in the data frame. The categories we will create will be based on using data from the summary statistics of the data frame. The categories will be based on the quartiles of the goals_and_assists column.
summary(general_df$goals_and_assists)
From the summary statistics, we can see that the quartiles of the goals_and_assists column are as follows:
- 1st Quartile: 8.00
- Mean: 12.03
- 3rd Quartile: 15.25
We will use these quartiles to create the categories for the box plot. The categories will be as follows:
- Low: 0 - 7.99
- Medium: 8 - 14.99
- High: >14.99
goals_assists <- general_df %>%
mutate(
category = case_when(
goals_and_assists <= 8 ~ "Low",
goals_and_assists > 8 & goals_and_assists <= 15 ~ "Medium",
goals_and_assists > 15 ~ "High"
)
)
Now we can create the box plot of the number of goals and assists by the teams in the 2024-2025 Uefa Conference League. We will use the ggplot2 package to create the box plot and the geom_boxplot function to plot the data. We will also use the theme_minimal function to set the theme of the plot to minimal. The geom_jitter function is used to add jitter to the box plot to show the individual data points.
ggplot(goals_assists, aes(
x = category, y = goals_and_assists)
) +
geom_boxplot(fill = "purple") +
geom_jitter(width = .2, height = 0, color = "black") +
scale_y_continuous(breaks = seq(0, 50, by = 5)) +
labs(title = "Box Plot of Goals and Assists in 2024-2025 Uefa Conference League",
x = "Goals and Assists Performance",
y = "Goals and Assists") +
theme_minimal()

The box plot shows the distribution of the number of goals and assists by the teams in the 2024-2025 Uefa Conference League. The box plot is a useful data visualization technique for visualizing the distribution of a variable and identifying patterns or trends that may be present in the data. From the box plot, we can see that the majority of teams fall into the medium category for goals and assists. The box plot provides a visual representation of the data and allows us to quickly identify the distribution of the number of goals and assists by the teams.
We can validate this finding by counting the number of teams in each category. We can use the table function to count the number of teams in each category. This will provide us with a frequency distribution of the number of teams in each category.
table(goals_assists$category)
The frequency distribution of the number of teams in each category is as follows:
- Low: 10 teams
- Medium: 17 teams
- High: 9 teams